Introduction
The String is one of the foundational data types that is widely used in (almost) every project.
When working with strings it’s essential to know how they are built under the hood.
In this article you will learn:
- What is behind the scene of Swift’s
StringandCharactertypes. - How Swift searches for a
Characterin aString. - Which problems random access may cause and how to use it efficiently.
Understanding Core Concepts
Swift String and Character types are fully Unicode-compliant.
-
Unicode scalar value is a unique 21-bit number. For instance,
1F468.
Swift allows defining a scalar directly in a string using"\u{your_hex_number}"format. -
Extended grapheme cluster is a collection of one or more unicode scalars.
The next string"\u{1F468}\u{200D}\u{1F4BB}"represents this 👨💻 emoji cluster.
Accessing String’s Characters
In Swift world, String does not allow accessing Characters by a simple integer-index.
Swift String defines String.Index type instead that consists of the following:
-
Position: an offset into the string’s code units
-
Transcoded offset: a sub-scalar offset, derived from transcoding
-
Grapheme cache: a value remembering the distance to the next grapheme boundary
-
Reserved: bits for future use
-
Scalar aligned: whether this index is scalar-aligned
As we can see, String.Index stores much more information than a usual Int-based index.
Searching for an Index
Swift provides index(_: offsetBy:) API to calculate a new index that is grounded on the base one with some offset. The startIndex and endIndex may be used as a starting point.
Note:
offsetmay be positive as well as negative for the forward/backward searching.
The only constraint here is not to exceed the indices bounds.
According to documentation, the time complexity of this call:
O(1) if the collection conforms to
RandomAccessCollectionand O(n) otherwise.
String does not conform to RandomAccessCollection. This knowledge will be handy for future examples.
Problem Statement
Let’s take a look what the time complexity is of the following code.
let string = "s-t-r-i-n-g"
let offsets = [0, 2, 4, 6, 8, 10]
for offset in offsets {
let index = string.index(string.startIndex, offsetBy: offset)
print(string[index], terminator: " ")
}
/// Prints: s t r i n g
Initially, the loop iterates through an array of offsets and prints a corresponding Character. This process is visualized in the next picture.
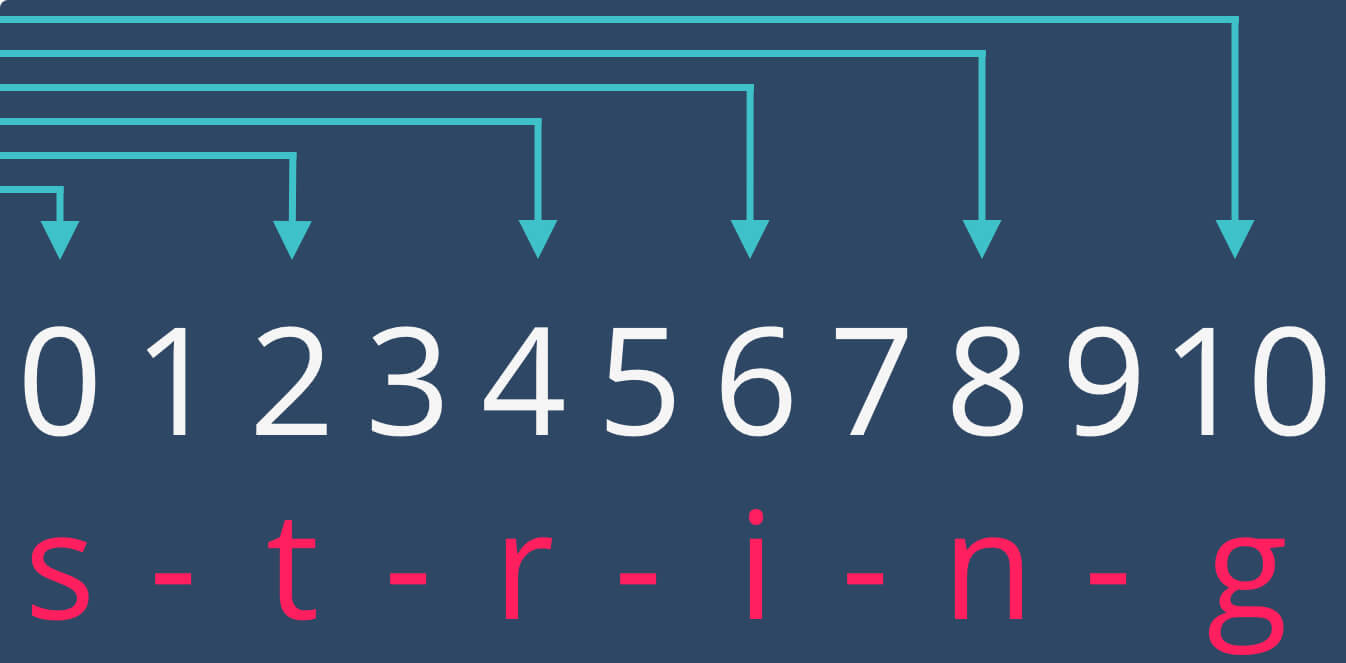
As we can see, each iteration involves searching for an index that takes max(offset) calls and there are array.count iterations.
In terms of Big O, the function grows as O(n*k) where both arguments tend towards infinity.
Reducing time complexity with extra memory
Let’s create an Array of characters as Array("s-t-r-i-n-g"). The Array allocates an underlying buffer with constant-size blocks to store elements.
Since Array conforms to RandomAccessCollection it does provide O(1) access and require O(n) memory.
let string = "s-t-r-i-n-g"
let offsets = [0, 2, 4, 6, 8, 10]
let arrayOfCharacters = Array(string)
for offset in offsets {
print(arrayOfCharacters[offset], terminator: " ")
}
/// Prints: s t r i n g
It seems like we can’t do better than O(1) time and O(n) space. However, at this point it’s crucial to know what happens under the hood.
Just take a closer look:
Arrayallocates an underlying buffer with constant-size blocks.
What is the size of these blocks? Since we store characters it’s the size of the biggest Character in a String.
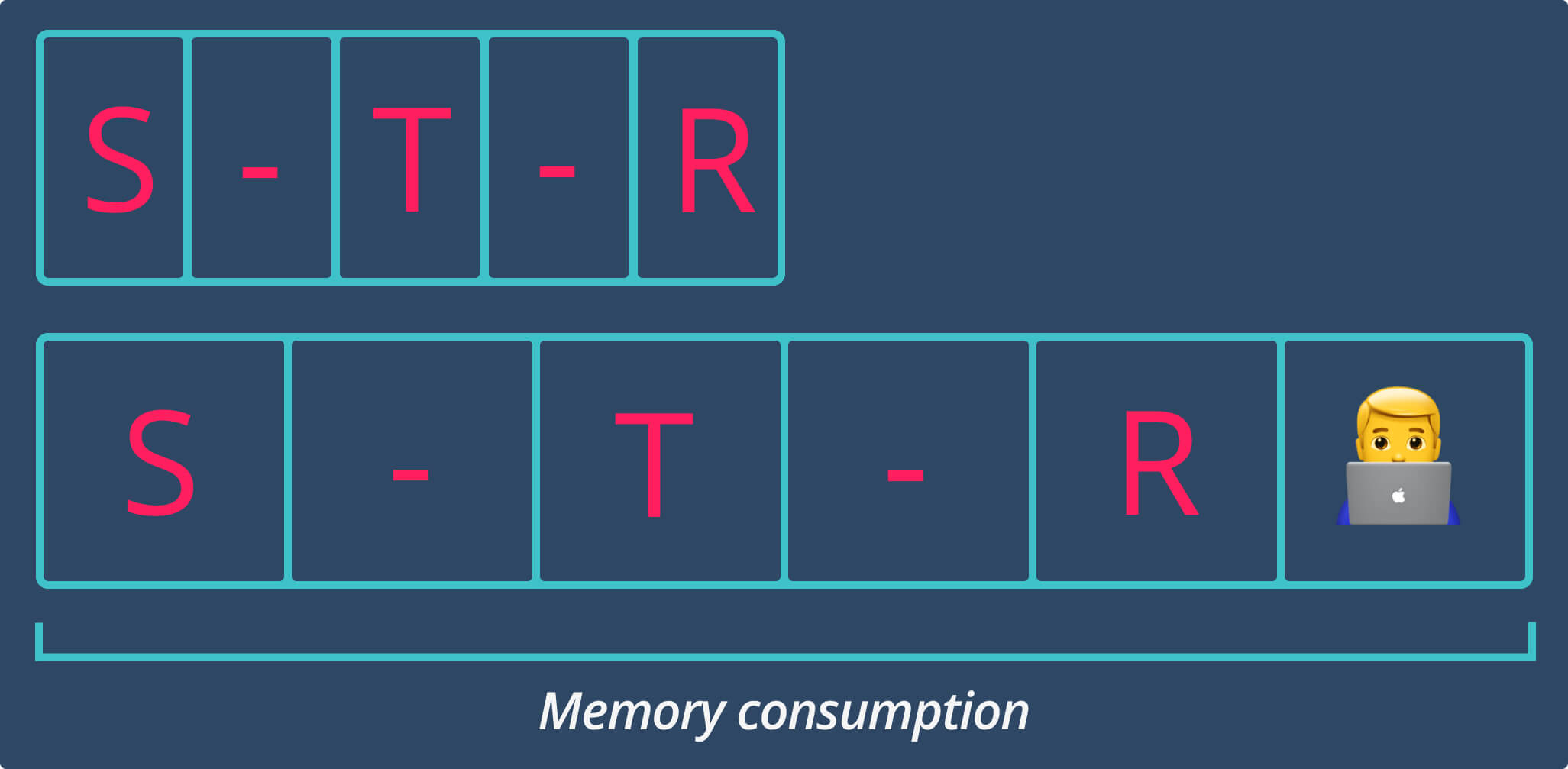
By default,
Charactertakes 16 bytes of memory.
If a string contains complex unicode scalars a Character may take extra memory.
In other words, Array allocates a number of memory blocks that are not fully used because of one complex Character.
Reducing memory consumption
Instead of storing variable-size Characters, we can store constant-size indices.
It allows mapping String.Index to Int-Offset and provides an O(1) access.
let string = "s-t-r-i-n-g"
let offsets = [0, 2, 4, 6, 8, 10]
let arrayOfIndices = Array(string.indices)
for offset in offsets {
print(string[arrayOfIndices[offset]], terminator: " ")
}
/// Prints: s t r i n g
The main difference is the allocation of 8-byte memory blocks (instead of 16-byte) and a guarantee that Array won’t ever extend them.
Can we do better?
Currently, there is O(1) time and O(n) memory complexity. Despite the fact that we use just 8-bytes per index, try to ask yourself the following questions:
- First of all, do we really need a random access to the whole string?
- Can we solve a problem by a forward/backward iteration?
- Can we use two pointers to reach the goal?
- Do we need access to an entire string instead of a small range?
- Can we use a simple stack/queue/whatever to hold a range of indices/characters?
- And so on…
The answers to these questions may lead you to a better time/memory trade-off.
Wrapping Up
Here are some tips for working with Swift Strings:
-
Tip 1: Use native
Stringiterators if possible and avoid an unnecessary calculation ofString.Indexby repetitively traversing an entire string. -
Tip 2: Consider creating an array of indices as a memory trade-off. It does provide a constant time access to the
Stringindices and can speed up a runtime of your algorithm. This is also useful in the time-bound environment, as for instance, during the coding interview when you do not have enough time to create a better solution. -
Tip 3: Consider the best-known algorithms on strings such as KMP, Aho–Corasick or Suffix Trees in the substring search.
-
Tip 4: Use
isEmptyinstead ofcount > 0if you just want to know whether a string is empty or not. Thecountproperty iterates a whole string to compose all unicode scalars, whereasisEmptyjust checks an underlyingStringGutsbuffer for emptiness.
All of the above tips may be handy in the case of long strings.
Further Reading
- Discover Side Tables - Weak Reference Management Concept in Swift.
Let’s take an in-depth look at weak references in Swift and learn concept of Side Tables.
By the way, let’s be friends on Twitter.